****NOTE: This Post for installing is obsolete and there are more better ways to launch a k8s cluster.
Kubernetes is a system for managing containerized applications in a clustered environment. It provides basic mechanisms for deployment, maintenance and scaling of applications on public, private or hybrid setups. It also comes with self-healing features where containers can be auto provisioned, restarted or even replicated.
![]()
In this blog post, i’ll show you how to install a Kubernetes cluster with three minions on CentOS 7, with an example on how to manage pods and services.
Kubernetes Components
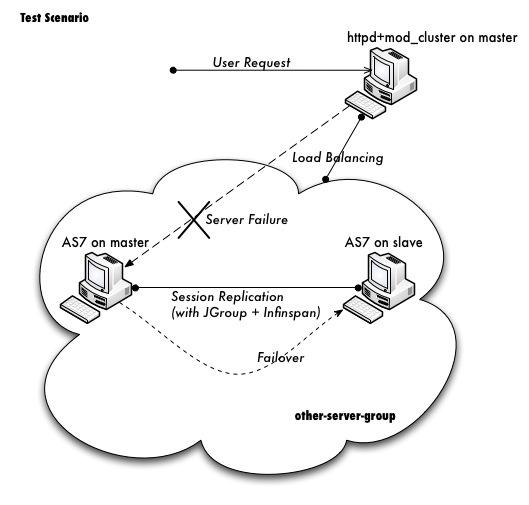
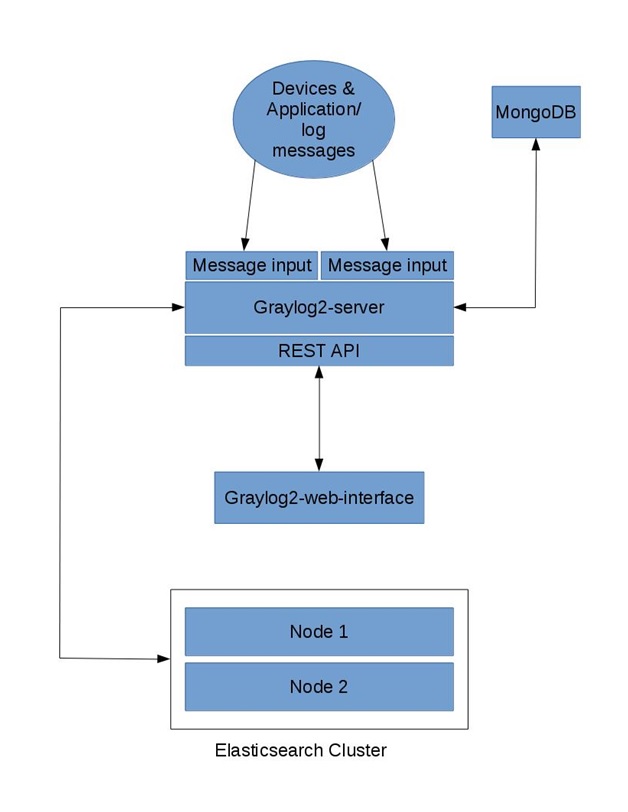
Kubernetes works in server-client setup, where it has a master providing centralized control for a number of minions. We will be deploying a Kubernetes master with three minions, as illustrated in the diagram further below.
Kubernetes has several components:
- etcd – A highly available key-value store for shared configuration and service discovery.
- flannel – An etcd backed network fabric for containers.
- kube-apiserver – Provides the API for Kubernetes orchestration.
- kube-controller-manager – Enforces Kubernetes services.
- kube-scheduler – Schedules containers on hosts.
- kubelet – Processes a container manifest so the containers are launched according to how they are described.
- kube-proxy – Provides network proxy services.
Deployment on CentOS 7
We will need 4 servers, running on CentOS 7.1 64 bit with minimal install. All components are available directly from the CentOS extras repository which is enabled by default. The following architecture diagram illustrates where the Kubernetes components should reside:

Prerequisites
- Disable iptables on each node to avoid conflicts with Docker iptables rules:
| $ systemctl stop firewalld
$ systemctl disable firewalld |
- Install NTP and make sure it is enabled and running:
| $ yum -y install ntp
$ systemctl start ntpd $ systemctl enable ntpd |
Setting up the Kubernetes Master (110.110.110.153)
The following steps should be performed on the master.
- Install etcd and Kubernetes through yum:
| $ yum -y install etcd kubernetes |
- Configure etcd to listen to all IP addresses inside /etc/etcd/etcd.conf. Ensure the following lines are uncommented, and assign the following values:
| ETCD_NAME=default
ETCD_DATA_DIR=”/var/lib/etcd/default.etcd” ETCD_LISTEN_CLIENT_URLS=”http://0.0.0.0:2379“ ETCD_ADVERTISE_CLIENT_URLS=”http://localhost:2379“ |
- Configure Kubernetes API server inside /etc/kubernetes/apiserver. Ensure the following lines are uncommented, and assign the following values:
| KUBE_API_ADDRESS=”–address=0.0.0.0″
KUBE_API_PORT=”–port=8080″ KUBELET_PORT=”–kubelet_port=10250″ KUBE_ETCD_SERVERS=”–etcd_servers=http://127.0.0.1:2379“ KUBE_SERVICE_ADDRESSES=”–service-cluster-ip-range=10.254.0.0/16″ KUBE_ADMISSION_CONTROL=”–admission_control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ResourceQuota” KUBE_API_ARGS=”” |
- Start and enable etcd, kube-apiserver, kube-controller-manager and kube-scheduler:
| $ for SERVICES in etcd kube-apiserver kube-controller-manager kube-scheduler; do
systemctl restart $SERVICES systemctl enable $SERVICES systemctl status $SERVICES done |
- Define flannel network configuration in etcd. This configuration will be pulled by flannel service on minions:
| $ etcdctl mk /atomic.io/network/config ‘{“Network”:”172.17.0.0/16″}’ |
- At this point, we should notice that nodes’ status returns nothing because we haven’t started any of them yet:
| $ kubectl get nodes
NAME LABELS STATUS |
Setting up Kubernetes Minions (Nodes)
The following steps should be performed on minion1, minion2 and minion3 unless specified otherwise.
- Install flannel and Kubernetes using yum:
| $ yum -y install flannel kubernetes |
- Configure etcd server for flannel service. Update the following line inside /etc/sysconfig/flanneld to connect to the respective master:
# Flanneld configuration options
# etcd url location. Point this to the server where etcd runs
FLANNEL_ETCD=”http://110.110.110.153:2379″
# etcd config key. This is the configuration key that flannel queries
# For address range assignment
FLANNEL_ETCD_KEY=”/atomic.io/network”
- Configure Kubernetes default config at /etc/kubernetes/config, ensure you update the KUBE_MASTER value to connect to the Kubernetes master API server:
# How the controller-manager, scheduler, and proxy find the apiserver
KUBE_MASTER=”–master=http://110.110.110.153:8080″
- Configure kubelet service inside /etc/kubernetes/kubelet as below:
minion:
# kubernetes kubelet (minion) config
# The address for the info server to serve on (set to 0.0.0.0 or “” for all interfaces)
KUBELET_ADDRESS=”–address=0.0.0.0″
# The port for the info server to serve on
KUBELET_PORT=”–port=10250″
# You may leave this blank to use the actual hostname
KUBELET_HOSTNAME=”–hostname-override=55.55.55.178″
# location of the api-server
KUBELET_API_SERVER=”–api-servers=http://110.110.110.153:8080″
# Add your own!
KUBELET_ARGS=””
- Start and enable kube-proxy, kubelet, docker and flanneld services:
| $ for SERVICES in kube-proxy kubelet docker flanneld; do
systemctl restart $SERVICES systemctl enable $SERVICES systemctl status $SERVICES done |
- On each minion, you should notice that you will have two new interfaces added, docker0 and flannel0. You should get different range of IP addresses on flannel0 interface on each minion, similar to below:
minion:
| $ ip a | grep flannel | grep inet
inet 172.17.45.0/16 scope global flannel0 |
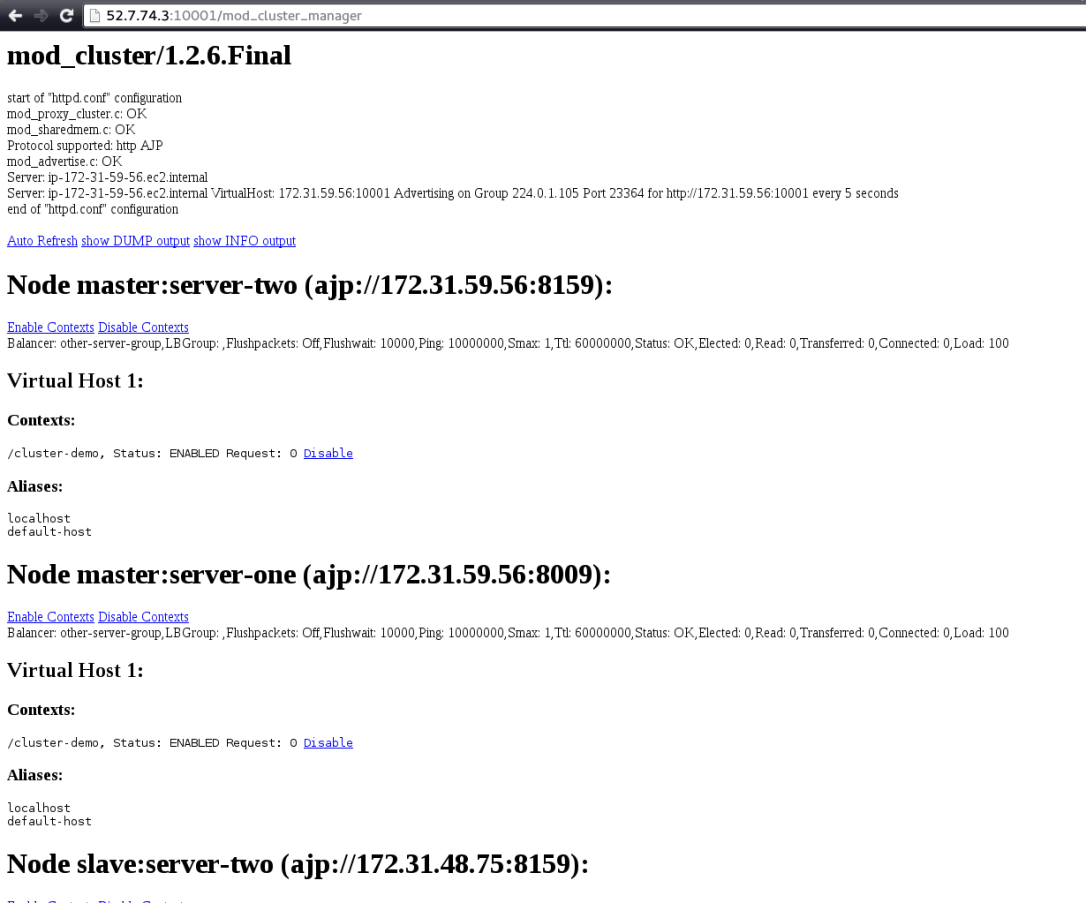
- Now login to Kubernetes master node and verify the minions’ status:
$ kubectl get nodes
NAME LABELS STATUS AGE
110.110.110.152 kubernetes.io/hostname=110.110.110.152 Ready 28m
127.0.0.1 kubernetes.io/hostname=127.0.0.1 NotReady 10d
55.55.55.178 kubernetes.io/hostname=55.55.55.178 Ready 10d
You are now set. The Kubernetes cluster is now configured and running. We can start to play around with pods.
Creating Pods (Containers)
To create a pod, we need to define a yaml file in the Kubernetes master, and use the kubectl command to create it based on the definition. Create a mysql.yaml file:
| $ mkdir pods
$ cd pods $ vim mysql.yaml |
And add the following lines:
#######################################
apiVersion: v1
kind: Pod
metadata:
name: mysql
labels:
name: mysql
spec:
containers:
– resources:
limits :
cpu: 1
image: mysql:latest
name: mysql
env:
– name: MYSQL_ROOT_PASSWORD
# change this
value: secret
ports:
– containerPort: 3306
name: mysql
############################
Create the pod:
| $ kubectl create -f mysql.yaml |
It may take a short period before the new pod reaches the Running state. Verify the pod is created and running:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
mysql 1/1 Running 0 17m
So, Kubernetes just created a Docker container on 192.168.50.132. We now need to create a Service that lets other pods access the mysql database on a known port and host.
Creating Service
At this point, we have a MySQL pod inside 192.168.50.132. Define a mysql-service.yaml as below:
####################################
apiVersion: v1
kind: Service
metadata:
labels:
name: mysql
name: mysql
spec:
type: NodePort
ports:
# the port that this service should serve on
– port: 3306
nodePort: 30001
protocol: TCP
# label keys and values that must match in order to receive traffic for this service
selector:
name: mysql
#####################################
Start the service:
| $ kubectl create -f mysql-service.yaml |
You should get a 10.254.x.x IP range assigned to the mysql service. This is the Kubernetes internal IP address defined in /etc/kubernetes/apiserver. This IP is not routable outside, so we defined the public IP instead (the interface that connected to external network for that minion):
| $ kubectl get services
NAME CLUSTER_IP EXTERNAL_IP PORT(S) SELECTOR AGE kubernetes 10.254.0.1 <none> 443/TCP <none> 14d mysql 10.254.134.162 nodes 3306/TCP name=mysql 18m Namespace: default Labels: name=mysql Selector: name=mysql Type: NodePort IP: 10.254.134.162 Port: <unnamed> 3306/TCP NodePort: <unnamed> 30001/TCP Endpoints: 10.20.21.2:3306 Session Affinity: None No events. |
Let’s connect to our database server from outside (we used MariaDB client on CentOS 7):
mysql -uroot -p –port=30001 -h55.55.55.178
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 5
Server version: 5.7.11 MySQL Community Server (GPL)
Copyright (c) 2000, 2015, Oracle, MariaDB Corporation Ab and others.
Type ‘help;’ or ‘\h’ for help. Type ‘\c’ to clear the current input statement.
MySQL [(none)]>
That’s it! You should now be able to connect to the MySQL container that resides on minion (55.55.55.178). Check out the Kubernetes examples contains a number of examples on how to run real applications with Kubernetes.
References:
https://www.vultr.com/docs/getting-started-with-kubernetes-on-centos-7
http://severalnines.com/blog/installing-kubernetes-cluster-minions-centos7-manage-pods-services
Problems:
Error – Pod “mysql” is forbidden: no API token found for service account default/default
solution or work around – Remove “ServiceAccount’’ in kubernetes API config /etc/kubernetes/apiserver
KUBE_ADMISSION_CONTROL=”–admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota”
Command Line way of creating pods, services and replication controllers:
start a simple demo service, scale it to multiple instances and list its running pods:
# Create demo service
$ kubectl run service-demo –image=geku/go-app:0.1 –port=5000
$ kubectl get pods -l run=service-demo
NAME READY STATUS RESTARTS AGE
service-demo-ixlrc 1/1 Running 0 3m
# Scale service to 3 instances
$ kubectl scale rc service-demo –replicas=3
$ kubectl get pods -l run=service-demo
NAME READY STATUS RESTARTS AGE
service-demo-df3el 1/1 Running 0 48s
service-demo-ixlrc 1/1 Running 0 4m
service-demo-l9zm8 1/1 Running 0 48s
The first command is actually a shortcut to create a ReplicationController which ensures we have the desired number of replicas running. With the last command we should see that Kubernetes started 3 instances of our service. We can list the ReplicationControllers too:
kubectl get rc
So, after having a service running, we would like to access it. But this is not possible yet because the ports of our service instances are not exposed and only accessible on our virtual machine. Let’s expose our service on port 80:
$ kubectl expose rc service-demo –port=80 –target-port=5000 –type=NodePort
This creates a load balancer and assigns our service a virtual IP where we can reach a random instance of our service. Additionally it maps it to a random port on our host server. To get the port run:
$ kubectl get -o yaml service/service-demo | grep nodePort
nodePort: 31538
In our case we can reach our service on port 31538. This might be different on your machine and you need to change it in the following command.
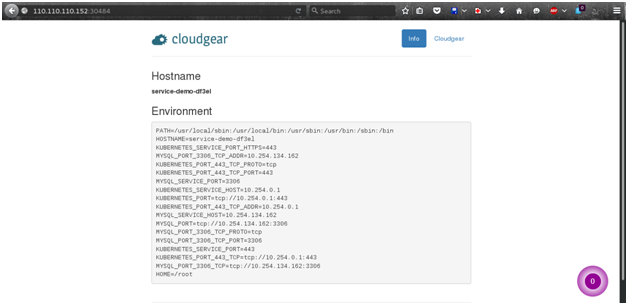
110.110.110.152 is the IP of host running this pod
$ curl 110.110.110.152:31538/json
{“hostname”:”service-demo-mltul”,”env”:[“PATH=/usr/loc…
$ curl 110.110.110.152:31538/json
{“hostname”:”service-demo-gh4ej”,”env”:[“PATH=/usr/lo
By sending multiple requests you can see that they are answered by different instances (varying hostname).
To remove all pods and the service you run:
$ kubectl delete service/service-demo
$ kubectl delete rc/service-demo
Resize replicas
$ kubectl resize –current-replicas=2 –replicas=3 rc flocker-ghost
Edit yaml files and update
$ kubectl update -f mysql-pod.yaml